
목차
torch.autograd를 사용한 자동 미분(Automatic differentiation with torch.autograd)
Tensor, Function과 연산 그래프(Tensors, Functions and Computational graph)
변화도 계산하기(Computing gradients)
변화도 추적 멈추기(Disabling gradient tracking)
연산 그래프에 대한 추가 정보(more on Computational Graphs)
선택적으로 읽기: 텐서 변화도와 야코비안 곱(Optional Reading: Tensor gradients and jacobian products)
Keywords: backpropagation, gradient, loss function, retraining, gradient descent, differentiation engine, computational graph, class Function in pytorch, forward direction, requires_grad property, grad_fn property, forward pass, backward pass, ∂loss/∂w, ∂loss/∂b, loss.backward(), w.grad, b.grad, leaf nodes, root node, backward call, retain_graph=True, torch.no_grad() block, gradient tracking, frozen parameter, fine tuning, autograd, directed acyclic graph, chain rule, dynamic graph, control flow statements, computation vs operation, cycle vs loop, scalar loss function, Jacobian matrix, vector function, Jacobian product, shape vs size on tensor, scalar-valued function, optimizer
torch.autograd를 사용한 자동 미분(Automatic differentiation with torch.autograd)
- 역전파: 신경망 훈련에 가장 자주 사용되는 알고리즘
손실 함수의 변화도(gradient)에 따라 매개변수(모델 가중치)를 조정
네트워크를 통해 역방향으로 이동하여 가중치와 편향을 조정하여 모델을 재훈련 - 손실 함수: 신경망의 예상 출력과 실제 출력 간의 차이를 계산
목표: 손실 함수를 0으로 최소화하는 것 - 경사하강법(gradient descent): 손실을 줄이기 위해 시간이 지남에 따라 모델을 재훈련(retraining)하는 프로세스
- PyTorch에는 그래디언트 계산을 위한 torch.autograd라는 미분 엔진이 내장되어 있음
- 다음과 같이 간단한 1계층 신경망 입력 x, 매개변수 w 및 b, 손실 함수를 사용하여 정의할 수 있음
import torch
x = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
Keywords: backpropagation, gradient, loss function, retraining, gradient descent, differentiation engine, computational graph
- backpropagation:
신경망을 훈련하는 데 사용되는 알고리즘으로, 각 계층에서 오류를 계산하고 그에 따라 가중치를 업데이트하는 데 사용됨 - gradient:
gradient descent과 같은 최적화 알고리즘에 사용되는 함수의 가장 급격한 증가(steepest increse)의 방향과 크기를 나타내는 벡터 - loss function:
모델을 최적화하는 데 사용되는 함수
신경망에서 예측된 출력과 실제 출력 간의 오차 또는 차이를 측정하는 데 사용되는 함수 - retraining:
성능을 향상시키기 위해 새로운 데이터에 대해 모델을 다시 훈련시키는 과정 - gradient descent:
gradient의 반대 방향으로 weights를 조정하여 신경망에서 loss function을 최소화하는 데 사용되는 최적화 알고리즘 - differentiation engine:
신경망의 다양한 연산에 대한 gradients를 계산하는 구성 요소(component)
backpropagation을 위한 gradients를 계산하는 데 사용됨 - computational graph:
수학적 계산의 그래프 표현
신경망에서 backpropagation하는 동안 gradients를 효율적으로 계산하는 데 사용됨
Tensor, Function과 연산 그래프(Tensors, Functions and Computational graph)
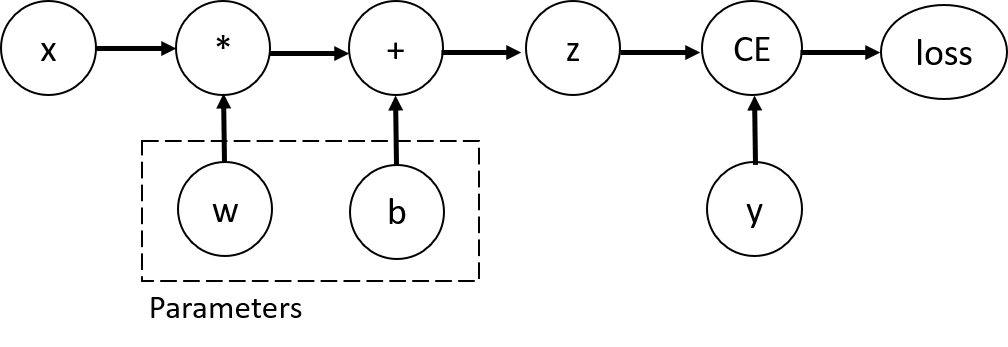
- 이 신경망에서는 매개변수 w와 b를 최적화해야 하고 기울기를 계산해야 함
- 그래디언트를 계산하려면 텐서의 requires_grad 속성 설정 필요
- 계산 그래프를 구성하기 위해 텐서에 적용되는 함수: Function 클래스의 개체
- 함수 개체는 순방향으로 함수를 계산하는 방법과 역방향 전파 중에 도함수를 계산하는 방법 알고 있음
- 역방향 전파 함수에 대한 참조(reference)는 텐서의 grad_fn 속성에 저장됨
- 텐서를 생성할 때(requires_grad=True 파라미터) 또는 나중에 x.requires_grad_(True) 메서드를 사용하여 requires_grad 값을 설정할 수 있음
print('Gradient function for z =',z.grad_fn)
print('Gradient function for loss =', loss.grad_fn)
Gradient function for z = <AddBackward0 object at 0x00000280CC630CA0>
Gradient function for loss = <BinaryCrossEntropyWithLogitsBackward object at 0x00000280CC630310>
Keywords: class Function in pytorch, forward direction, requires_grad property, grad_fn property, forward pass, backward pass
- class 'Function' in pytorch:
신경망의 모든 작업에 대한 기본 클래스로 단일 정방향 계산을 나타냄 - forward direction:
일반적으로 입력에서 출력으로 신경망에서 계산이 수행되는 방향 - require_grad property:
PyTorch 텐서의 속성
역방향 전달(backward pass) 중에 텐서에 대한 그래디언트를 계산해야 하는지 여부를 나타냄 - grad_fn property:
텐서를 생성한 함수를 참조하는 PyTorch 텐서의 속성
그래디언트를 계산하기 위해 backward pass에 사용됨 - forward pass:
입력이 주어진 신경망의 출력을 계산하는 프로세스
입력 텐서로 시작하여 계산 그래프의 Function 클래스에 의해 정의된 일련의 작업을 적용하여 한 작업의 출력을 다음 작업의 입력으로 전달
forward pass의 결과는 일반적으로 loss 함수를 계산하는 데 사용되는 출력 텐서 - backward pass:
모델의 매개변수에 대한 loss 함수의 그래디언트를 계산하는 프로세스
일반적으로 loss 텐서인 루트 노드에서 시작하여 chain rule of differentiation을 적용하여 계산 그래프의 모든 텐서에 대한 그래디언트를 계산
그래디언트는 텐서의 grad 속성에 저장되며 옵티마이저를 사용하여 모델의 매개변수를 업데이트하는 데 사용할 수 있음
backward pass는 루트 텐서에서 backward() 메서드를 호출하여 수행됨
class 'Function' in pytorch 상세
PyTorch의 Function 클래스는 신경망에서 계산을 만들고 표현하기 위한 기본 빌딩 블록입니다. 행렬 곱셈 또는 비선형 활성화 함수와 같은 특정 연산의 정방향 계산을 정의하는 데 사용됩니다. 또한 그래디언트를 계산하기 위해 역방향 패스에서 사용되는 계산의 입력 및 출력 텐서에 대한 정보를 보유합니다.
사용자는 Function을 서브클래싱하고 입력 텐서에서 수행되는 계산을 정의하고 출력 텐서를 반환하는 전달 메서드를 구현하여 새 작업을 정의할 수 있습니다. 입력 텐서에 대한 기울기를 계산하는 역방향 방법은 autograd 패키지를 사용하여 PyTorch에 의해 자동으로 정의됩니다.
신경망에서 계산이 수행되면 PyTorch는 해당 Function 클래스의 인스턴스를 생성하고 전달 메서드를 호출합니다. 순방향 메서드에서 반환된 출력 텐서는 grad_fn 속성과 연결되어 있어 PyTorch가 계산을 추적하고 역방향 패스 중에 그래디언트를 계산할 수 있습니다.
또한 기본적으로 PyTorch에 의해 생성된 모든 텐서에는 require_grad=False가 있습니다. 즉, 이 텐서에 대한 그래디언트는 역방향 패스 중에 계산되지 않습니다. 그러나 텐서에 require_grad=True를 설정하면 그래디언트가 계산되어 텐서를 역방향 전달에 사용할 수 있고 사용자가 최적화 프로그램을 사용하여 모델의 매개변수를 업데이트할 수 있습니다.
The Function class in PyTorch is a fundamental building block for creating and representing computations in a neural network. It is used to define the forward computation of a specific operation, such as a matrix multiplication or a non-linear activation function. It also holds information about the input and output tensors of the computation, which are used in the backward pass to compute gradients.
A user can define a new operation by subclassing Function and implementing the forward method, which defines the computation performed on the input tensors and returns the output tensors. The backward method, which computes gradients with respect to the input tensors, is automatically defined by PyTorch using the autograd package.
When a computation is performed in a neural network, PyTorch creates an instance of the corresponding Function class and calls its forward method. The output tensors returned by the forward method are associated with the grad_fn property, which allows PyTorch to trace the computation and compute gradients during the backward pass.
It is also worth noting that, by default, all tensors created by PyTorch have requires_grad=False, which means that gradients with respect to these tensors will not be computed during the backward pass. However, by setting requires_grad=True on a tensor, gradients will be computed, allowing the tensor to be used in the backward pass and allowing the user to update the model's parameters using the optimizer.
변화도 계산하기(Computing gradients)
- 신경망에서 매개변수의 가중치를 최적화하려면 매개변수에 대한 손실 함수의 도함수 계산 필요
- 이를 위해서는 x 및 y의 일부 고정 값에 대해 ∂loss/∂w 및 ∂loss/∂b 계산 필요
- 이러한 도함수를 계산하기 위해 loss.backward() 메서드가 호출됨
- 이후 w.grad 및 b.grad에서 값 검색 가능
loss.backward()
print(w.grad)
print(b.grad)
tensor([[0.2739, 0.0490, 0.3279],
[0.2739, 0.0490, 0.3279],
[0.2739, 0.0490, 0.3279],
[0.2739, 0.0490, 0.3279],
[0.2739, 0.0490, 0.3279]])
tensor([0.2739, 0.0490, 0.3279])- 기울기(gradient, grad 속성)는 require_grad 속성이 True로 설정된 계산 그래프의 리프 노드에만 사용할 수 있음
- 그래프의 다른 노드에는 그라디언트를 사용할 수 없음
- backward를 사용한 기울기 계산은 성능상의 이유로 지정된 그래프에서 한 번만 수행할 수 있음
- 동일한 그래프에서 여러 개의 backward 호출(calls)이 필요한 경우 retain_graph=True 매개변수를 backward 호출에 전달해야 함
키워드: ∂loss/∂w, ∂loss/∂b, loss.backward(), w.grad, b.grad, leaf nodes, root node, backward call, retain_graph=True
- ∂loss/∂w, ∂loss/∂b:
각각 weight 및 bias 변수에 대한 손실 함수의 편도함수(partial derivatives)
weight 또는 bias의 작은 변화(small change)에 대한 손실 함수의 변화를 나타냄 - loss.backward():
PyTorch에서 손실 변수(loss variable)로 표시되는 계산의 입력 텐서에 대한 그래디언트를 계산하는 데 사용되는 메서드
loss variable의 grad_fn 속성과 연결된 Function 클래스의 backward 메서드로 계산된 그래디언트를 사용함
It uses the gradients computed by the backward method of the Function class associated with the grad_fn property of the loss variable. - w.grad, b.grad:
각각 weight 및 bias 변수의 기울기
역방향 패스 후 PyTorch에 의해 자동으로 계산됨
옵티마이저를 사용하여 가중치 및 편향 변수를 업데이트하는 데 사용할 수 있음 - leaf node:
하위 노드가 없는 계산 그래프의 텐서
그래프에 대한 입력 텐서이며 일반적으로 require_grad=True를 가짐 - root node:
backward pass가 시작되는 텐서
일반적으로 loss 텐서이며 forward pass의 마지막 연산 - backward call:
backward() call은 루트 노드에서 시작하여 계산 그래프의 모든 텐서에 대한 그래디언트를 계산하는 데 사용됨
그래프를 역방향으로 탐색하고 미분의 연쇄 법칙(chain rule)을 사용하여 그래디언트를 계산 - retain_graph=True:
backward() 메서드에 전달할 수 있는 선택적 매개변수
기본적으로 retain_graph=False는 백워드 패스 후에 그래프가 해제됨을 의미
retain_graph=True이면 그래프가 유지되고 다른 역방향 전달에 사용될 수 있음
변화도 추적 멈추기(Disabling gradient tracking)
- 기본적으로, require_grad=True인 텐서는 계산 기록을 추적하고 그래디언트 계산을 지원
- 학습된 모델을 입력 데이터에 적용만 하는 순전파 연산만 필요한 경우와 같이 추적 및 그래디언트 계산이 필요하지 않은 경우 존재
- 이러한 경우 코드를 torch.no_grad() 블록으로 둘러싸서 추적 중지할 수 있음
- detach() 메소드도 동일하게 추적 중지할 수 있음
z = torch.matmul(x, w)+b
print(z.requires_grad)
with torch.no_grad():
z = torch.matmul(x, w)+b
print(z.requires_grad)
z = torch.matmul(x, w)+b
z_det = z.detach()
print(z_det.requires_grad)
True
False
False변화도 추적을 멈춰야 하는 이유들
- 신경망의 일부 매개변수를 고정으로 표시(frozen parameter)
이는 사전 훈련된 네트워크를 미세 조정하기 위한 일반적인 시나리오 - 그래디언트 추적이 없는 텐서에 대한 계산이 더 효율적이기 때문에 순방향 패스만 수행할 때 계산 속도 향상
Keywords: torch.no_grad() block, gradient tracking, frozen parameter, fine tuning
- torch.no_grad() block:
그래디언트 추적을 일시적으로 비활성화하는 PyTorch에서 제공하는 컨텍스트 관리자
그래디언트 추적이 비활성화되면 포워드 패스가 평소와 같이 수행됨
그러나 그래디언트가 계산되지 않고 텐서의 grad 속성이 업데이트되지 않음
그래디언트가 필요하지 않을 때 계산 속도를 높이고 메모리를 절약하는 데 유용할 수 있음 - gradient tracking:
backward pass 동안 모델의 매개변수와 관련하여 loss 함수의 기울기를 계산하고 저장하는 프로세스
PyTorch의 autograd 패키지에 의해 수행되며 requires_grad=True인 모든 텐서에 대해 기본적으로 활성화 - frozen parameter:
기울기 추적이 비활성화된 매개변수
backward pass 중에 업데이트할 수 없음
require_grad=False를 설정하거나 매개변수를 torch.no_grad() 블록 내부에 배치하여 수행할 수 있음 - fine tuning:
새로운 작업에 대해 사전 훈련된 모델을 훈련하거나 업데이트하는 프로세스
고정된 매개변수의 일부 또는 전부를 고정 해제하고 훈련 중에 업데이트하여 수행할 수 있음
사전 훈련된 모델이 새 작업에 유용한 기능을 학습했고 이 지식을 활용하여 성능을 향상시키려는 경우에 유용
연산 그래프에 대한 추가 정보(more on Computational Graphs)
- autograd
- DAG에 데이터(텐서) 기록
- DAG에 실행된 모든 연산들(결과 텐서 생성 포함) 기록
- 방향성 비순환 그래프(DAG): Function 객체로 구성
- 잎(leaves): 입력 텐서
- 뿌리(root): 결과 텐서
- 그래프 추적: 체인 규칙을 사용하여 변화도 자동 계산
- 순전파 단계(forward pass):
- 요청된 연산 수행: 결과 텐서를 계산
- 변화도 기능(gradient function): DAG에서 유지
- 역전파 단계(backward pass):
- .backward()가 DAG 루트에서 호출될 때 시작
- 변화도 계산: 각 .grad_fn에서
- 변화도 누적(accumulate): 각 텐서의 .grad 속성에서
- 전파(propagate): 체인 규칙을 사용하여 잎(leaf) 텐서까지
- PyTorch의 DAG: 동적(dynamic)
- 그래프 재생성(recreate) 및 채움(populate): 각 .backward() 호출 후 처음부터
- 모델에서 제어 흐름(control flow) 문 허용됨
- 모양(shape), 크기(size), 연산(operation): 모든 반복(iteration)에서 변경될 수 있음
키워드: autograd, directed acyclic graph, chain rule, dynamic graph, allowing control flow statements, computation vs operation, cycle vs loop
- Autograd:
텐서의 모든 작업에 대한 자동 미분를 제공하는 PyTorch 모듈
신경망의 backward pass 중에 변화도를 계산하는 데 사용되어 훈련 중에 변화도를 효율적으로 계산할 수 있음 - Directed Acyclic Graph(DAG):
edge가 방향을 가져 방향이 있는 그래프를 형성하는 일종의 그래프 데이터 구조
cycle이나 loop가 없음 - 연쇄 법칙(chain rule):
합성 함수의 도함수는 구성 함수의 도함수를 곱하여 계산할 수 있다는 미적분학의 기본 개념
신경망에서 체인 규칙은 네트워크의 각 계층에 규칙을 반복적으로 적용하여 역방향 통과 중에 기울기를 계산하는 데 사용됨 - 동적 그래프(dynamic graph):
동적으로 변경될 수 있는 그래프
즉, 런타임 중에 그래프가 변경될 수 있음
더 많은 유연성을 허용하고 네트워크의 순방향 전달에서 루프 및 조건문과 같은 제어 흐름 문을 사용할 수 있게 함 - 제어 흐름 문 허용(allowing control flow statement):
Pytorch는 동적 그래프 기능을 사용하여 네트워크의 순방향 전달에서 제어 흐름 문을 사용할 수 있음
이를 통해 더 복잡한 신경망 아키텍처를 만들 수 있지만 계산 그래프가 더 복잡해지고 성능에 영향을 미칠 수 있음 - computation vs operation:
computation은 최종 출력을 생성하기 위해 텐서에서 수행되는 sequence of operations
신경망에서의 layer 및 activation function 등을 통한 forward pass
operation은 행렬곱, non-linear activation function과 같은 computation의 단일 단계 - cycle vs loop
cycle은 동일한 노드를 여러 번 방문할 수 있는 그래프의 닫힌 경로
loop는 특정 조건이 실행될 때까지 반복적으로 실행되는 일련의 명령
DAG 맥락에서 cycle은 동일한 노드로의 재방문을 의미, 비주기적이므로 DAG에서 허용되지 않음 -> Q) RNN에서는?
DAG 맥락에서 loop는 forward pass 중 발생하는 계산의 반복을 의미 -> Q) RNN에서는?
선택적으로 읽기: 텐서 변화도와 야코비안 곱(Optional Reading: Tensor gradients and jacobian products)
- 스칼라 손실 함수: 일부 매개변수에 대한 기울기
- 출력 함수가 임의의(arbitrary) 텐서인 경우 있음
- PyTorch: Jacobian 곱 계산. 실제 gradient 아님
- 벡터 함수: y = f(x), 여기서 x = <x1, ..., xn> 및 y = <y1, ..., ym>
- x에 대한 y의 기울기: Jacobian 행렬, Jij = ∂yi/∂xj
- Jacobian 행렬: 직접 계산되지 않음
- jacobian 곱: 주어진 입력 벡터 v = (v1 ... vm)에 대한 vT⋅J
- backward 함수: v를 인수로 사용하여 호출
- v의 크기(size): 곱을 계산하려고 하는 원래 텐서의 크기와 같아야 함
inp = torch.eye(5, requires_grad=True)
out = (inp+1).pow(2)
out.backward(torch.ones_like(inp), retain_graph=True)
print(f"First call\n{inp.grad}")
out.backward(torch.ones_like(inp), retain_graph=True)
print(f"\nSecond call\n{inp.grad}")
inp.grad.zero_()
out.backward(torch.ones_like(inp), retain_graph=True)
print(f"\nCall after zeroing gradients\n{inp.grad}")
tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.],
[2., 2., 2., 2., 4.]])
Second call
tensor([[8., 4., 4., 4., 4.],
[4., 8., 4., 4., 4.],
[4., 4., 8., 4., 4.],
[4., 4., 4., 8., 4.],
[4., 4., 4., 4., 8.]])
Call after zeroing gradients
tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.],
[2., 2., 2., 2., 4.]])
- 동일한 인자로 backward 두 차례 호출하면 변화도 값 달라짐
- pytorch가 backward propagation 수행 시 변화도를 누적하기 때문에 발생
- 계산 그래프의 모든 리프 노드의 grad 속성에 더해짐
- 적절한 변화도 계산을 위해 grad 속성을 0으로 만들어야 함
- 옵티마이저: 실제 학습 시 grad 속성을 0으로 만드는 데 도와줌
- backward() 함수: 위 코드에서 매개변수 없이 호출됨
- backward(torch.tensor(1.0)) 호출과 동일
- 신경망 훈련 중 loss와 같은 스칼라 값 함수의 변화도 계산에 유용함
- 키워드: 역전파, Pytorch, 그래디언트, 누산, 옵티마이저, 스칼라 값 함수, 신경망 훈련.
Keywords: scalar loss function, Jacobian matrix, vector function, Jacobian product, shape vs size on tensor, scalar-valued function, optimizer
- 스칼라 손실 함수(Scalar Loss Function):
모델의 예측값과 정답값을 취하여 이들 사이의 불일치(discrepancy, 차이)를 측정 후 스칼라 값을 반환하는 함수
예) Mean Squared Error, Binary Cross-Entropy
모델의 예측 출력과 실제 출력 간의 차이를 최소화하여 신경망을 훈련하는 데 사용됨 - 자코비안 행렬(Jacobian matrix):
벡터 함수의 모든 1차 편미분 행렬
신경망에서는 모델의 매개변수에 대한 손실 함수의 기울기를 계산하는 데 사용됨
신경망의 역방향 통과 동안 기울기를 계산하는 데 사용되는 자동 미분의 기본 개념 - 벡터 함수(vector function):
하나 이상의 입력을 받아 벡터 출력을 반환하는 함수
신경망에서 모델의 정방향 전달(forward pass)은 입력이 벡터이고 출력도 벡터인 벡터 함수로 생각할 수 있음 - 자코비안 곱(Jacobian Product):
자코비안 행렬과 벡터의 곱
자코비안 행렬은 벡터 함수의 모든 1계 편도함수의 행렬
벡터는 그래디언트가 계산되는 방향
특정 방향의 입력에 대한 함수의 기울기를 계산하는 데 사용됨 - Tensor의 모양 대 크기(shape vs size):
PyTorch에서 Tensor는 다차원 배열
텐서의 모양은 텐서의 각 차원의 크기를 나타내는 튜플
텐서의 크기는 모양의 곱인 텐서의 총 요소 수
예) 텐서의 모양이 (2,3)이라면 크기는 6
모양은 데이터의 구조를 이해하는 데 유용
크기는 데이터의 양을 이해하는 데 유용 - 스칼라 값 함수(scalar-valued function):
하나 이상의 입력을 받아 단일 스칼라 출력을 반환하는 함수
머신러닝에서 cost 또는 loss function을 나타내 신경망을 훈련하는 데 사용됨 - 옵티마이저(optimizer):
손실 함수와 같은 스칼라 값 함수를 최소화하기 위해 모델의 매개변수를 조정하는 데 사용되는 알고리즘
예) Stochastic Gradient Descent(SGD), Adam, Adagrad
learning rate 등의 자체 하이퍼 매개변수 세트 존재
'Pytorch > 튜토리얼' 카테고리의 다른 글
| [PyTorch] 공식 문서 Learn the Basics 요약 - 7. Save and load the model (0) | 2023.01.21 |
|---|---|
| [PyTorch] 공식 문서 Learn the Basics 요약 - 6. Optimization (0) | 2023.01.20 |
| [PyTorch] 공식 문서 Learn the Basics 요약 - 4. Build Model (0) | 2023.01.18 |
| [PyTorch] 공식 문서 Learn the Basics 요약 - 3. Transforms (0) | 2023.01.16 |
| [PyTorch] 공식 문서 Learn the Basics 요약 - 2. Dataset and DataLoaders, Normalization (0) | 2023.01.16 |